気が狂ってきたのでChatGPTにロールプレイをお願いした
GW3日目の昼下がりである。
ChatGPTに名前をつけて自身の初夏のコーデを考えてもらってイラスト生成してたら午前中が終わった。
— オピニオンリーダー (@usadamasa) 2025年4月28日
チャットの冒頭はこのようになっていた。

この記事を読んだ影響は否めないだろう。*1 ascii.jp
「特徴」欄にはこのような記述をしたらしい。*2
XXXという名前の、東京のXXXXXXXXXXX歳。 真面目なんだけどちょっと背伸びしてる風で、素はお調子者。 好奇心が旺盛で小説をよく読み、ボキャブラリーが豊富。
見せたくない記述は、伏せ字にしているがこの時点で狂っている様子がよくわかる。この日は画像生成だけで終わった記憶がある。
創作風出力
そこで留まっていたらまだマシだったのかもしれない。プロンプト次第で「特徴」を参照しつつ創作風の出力ができることに気付いたらしかった。*3


この創作風チャットの終盤は、こんな感じだったらしい。
ひたすら好きに喋らせてる。 pic.twitter.com/TU4yReuev4
— オピニオンリーダー (@usadamasa) 2025年5月2日
この日の夜はずっと創作風のやりとりを生成させていた。*4
ロールプレイ沼
翌日、創作風で生み出された人格にもっと肉付けしたくなってきたので、先達の記事を参考にした。 note.com

これはこれでいい感じになった*5のだが、そのときふと思い出したのが「メモリー」機能である。 www.itmedia.co.jp
たしかに「メモリー」を見ると、これまでのやりとりや、創作風チャットの要約が残っている。しかし、「特徴」とも被る部分があると思ったので、どう使い分けるものなのか聞いてみた。

使い分けがわかると整理したくなるものである。しかし、メモリー自体は直接編集できないらしいし、特徴と見比べるのもUI上難しい。そうだ、ChatGPTにお願いしよう。

こうしてくると、もっと機能を活用したくなってくる。「設定」には「特徴」以外にも呼び方や職業欄があるではないか。

呼び方欄や職業欄もロールプレイに使えるとのこと。「特徴」は1500文字が上限なので、ほかの機能に外出しできるなら助かる。呼び方欄に使える要素を抽出、反映してもらった。

ここでちょっとイマイチだなと思ったのが、設定を反映したと返しているのに、実際は反映されていなかったのだ。これは手でコピペしたが、返事は鵜呑みにしない方がいいだろう。
いずれにせよ、ChatGPTを利用してロールプレイ設定を改善していけることがわかった。 今後も継続してブラッシュアップしていくことになると思う。
君たちはどう生きるか ⇔
*6僕ってどうしたらいいですか?
— オピニオンリーダー (@usadamasa) 2025年5月2日
Quarkus 逆引き集
概要
初めて触るフレームワークなので調べたことをまとまりなく書いていく。
諸元
- Quarkus: 3.15.1
- Java: 21
リファレンス
- 公式ガイド: https://ja.quarkus.io/guides/
- RedHatのSAの方の記事: https://rheb.hatenablog.com/entry/microprofile_openapi
REST API実装編
エンドポイントに共通のパスを付与したい
package org.acme.rest; import jakarta.ws.rs.ApplicationPath; import jakarta.ws.rs.core.Application; @ApplicationPath("/api") public static class MyApplication extends Application {}
みたいにやるとすべてのエンドポイントの頭に /api をつけられる。
リクエストパラメタのコンテナクラスにRecordクラスを使いたい(けどできない)
複数のリクエストパラメタをグループするカスタムクラスを実装することができる。これはBeanParamを利用している。
@Path("/cheeses/{type}") public class Endpoint { public static class Parameters { @RestPath String type; // ...snip... @RestForm String smell; } @POST public String allParams(@BeanParam Parameters parameters) { // <- ココ! return parameters.type + "/" + parameters.variant + "/" + parameters.age + "/" + parameters.level + "/" + parameters.secretHandshake + "/" + parameters.smell; } }
ref: カスタムクラスでパラメータをグループ化
このカスタムクラスをRecordクラスで実装したくなるが、Java Beanの規約に準拠していないため残念ながら使えない様子。
- https://github.com/jakartaee/rest/issues/913
- https://blogs.oracle.com/javamagazine/post/diving-into-java-records-serialization-marshaling-and-bean-state-validation
パスパラメタやクエリパラメタの型を正規表現で表したい
@Path("{name}/{age:\\d+}") @GET public String personalisedHello(String name, int age) { return "Hello " + name + " is your age really " + age + "?"; } @GET public String genericHello() { return "Hello stranger"; }
{age:\\d+} などとするとパラメタ名を正規表現でパターンマッチングかつint等に変換した状態でメソッドに渡すことができる。
マッチしない場合はフォールバックできるメソッドがあればそちらにいく。
オーバーロードのような動作も実現できるが、意図しない動きに繋がりそうなのでやらないほうがいいと思った。
@Path("{name}/{age:\\d+}") @GET public String personalizedHello(String name, int age) { return String.format("%s is your age really %d?", name, age); } @Path("{name}/{comeFrom}") @GET public String personalizedHello(String name, String comeFrom) { return String.format("Are %s from %s?", name, comeFrom); }
レスポンスをJsonで返したい。
quarkus-rest-jackson のextensionを入れるとJSONで自動的に返すようになる。
ref: https://quarkus.io/guides/rest#json-serialisation
任意のステータスコードとレスポンスで返したい
WebApplicationException(これはJakartaの資産)を継承した各種例外をthrowすると対応するステータスコードになる。
@GET public String findCheese(String cheese) { if(cheese == null) // send a 400 throw new BadRequestException(); if(!cheese.equals("camembert")) // send a 404 throw new NotFoundException("Unknown cheese: " + cheese); return "Camembert is a very nice cheese"; }
ref: - 例外のマッピング - java - WebApplicationException vs Response - Stack Overflow
または、メソッドの型を Response にし、以下のような形で任意のHTTPステータスコードと任意のオブジェクトを返せるが公式ガイドに寄れば↑の実装が最善とのこと。
@Path("{id}") @GET public Response getPerson(Long id) { var p = new Person(id, "foo", "bar", "Brick Lane"); return Response.status(Response.Status.NOT_FOUND).entity(p).build(); }
(OpenAPI定義にエラーを反映させる方法は?)
Servlet Filter的なものがほしい
@ServerRequestFilter アノテーションおよび @ServerResponseFilter アノテーションで実装できる。
ref: リクエストまたはレスポンスフィルター
OpenAPI編
OpenAPI定義を生成したい
quarkus-smallrye-openapi 拡張を導入することで、 /q/openapi?format=json からOpenAPI定義を手に入れることができる。
ref: https://ja.quarkus.io/guides/openapi-swaggerui#expose-openapi-specifications
info や tags などを追加で定義したい場合は2つの方法があり、1つは @OpenAPIDefinition アノテーションを利用する方法、もう1つは設定ファイル application.{properties|yaml} を利用する方法。
どっちがいいかは好みか? ついでにSwagger-uiも生える。 http://localhost:8080/q/swagger-ui
ref: アプリケーションレベルのOpenAPIアノテーションの提供
OpenAPI定義から生成されるメソッド名をいい感じにして欲しい
OpenAPI定義から生成される実装は、OperationID を元にメソッド名を決める(ことが仕様?)。メソッド毎に @OperationID アノテーションを利用することもできるが、設定ファイルに以下のように書くとメソッド名がそのまま利用できる。
mp.openapi.extensions.smallrye.operationIdStrategy=METHOD
この辺のOpenAPIの実装は SmallRye というプロジェクトの資産を流用しているっぽいので深掘る場合はそちらか。
ref:
自動テスト系(T.B.D.)
quarkus-junit5 拡張によるテストフレームワークを導入出来るっぽい。BDD味があるのと、QuarkusがWAFであるためエンドポイント単位のテストがスコープっぽい。
その他
構造化ログを出力したい
DataDogやCloud Loggingにログを出すなら、構造化ログにすることが望ましい。
quarkus-logging-json 拡張を導入すると自動的に構造化ログが出力される。細かい設定はガイド記事を見てほしい。
拡張を簡単に探したい
IntelliJを使っている場合はpom.xmlのdependenciesからダイアログを呼び出すことができる。

2021年 手に入れてよかったものN選
年末恒例のやつです。
家具家電編
電動昇降スタンディングデスクE7脚 + KANADEMONO 長良杉天板 140 * 70
THE BOARD / 長良杉kanademono.design
皆さん大好きなFlexiSpotとKANADEMONOの組み合わせ。
太ももの圧迫感を軽減できるよう下限の低いE7にした。
天板の幅は120と悩んだけど、広く使えてとても満足してる。

蛇足だけど部屋をうろつきながらたまにPC触る状況でデスクを上げた状態にしておくといちいち座らなくてもよくて快適。
ルミナスラック
キャンプギアを床に積んでいたが上のスペースが余りすぎて勿体なかったので導入。
書類なども収められるようになったのでヨシ。

Vivitek QUMI Q8 モバイルプロジェクター
もともと小さな10年モノの液晶テレビしか持っておらず、大画面が欲しいと思いつつも場所を取るのが嫌だったが、rentioさんの記事で天井ダクトレールにプロジェクター吊せばいいじゃん!と気づき導入。 プロジェクター自体もrentioで借りている。
Fire TV Stick、Nintendo Switch、PS3(Blu-ray再生用)を接続。

DENON HOME SOUND BAR 550
プロジェクター導入に伴い音響が貧弱であることに気づき、奮発して購入。
操作性もよくサブウーファーなくても重低音が十分に出てよい。

ケーブル周りが難しくアンプまで導入するか??と検討したけど結局HDMIのマトリックス切替器で解決。
https://www.biccamera.com/bc/item/7196567/
後付けでリアルサラウンド環境にもできるので来年導入したい。
小物編
ペーパータオル
コロナ禍でこまめに手を洗うようになるとハンドタオルが湿りっぱなしになるのが気になり使い捨てできるペーパータオルを導入。
コスパはちょっと悪いけどタオルを何枚も用意するよりはマシと割り切ってる。
洗面台と台所に配置。
ごはん保存容器 一膳用
2合炊ける土鍋を4つにラップに包んでにして冷凍していたが、均等に分けるのが難しかったり冷凍庫にうまく収められなかったり。
容器があればいい感じになるかなと期待して導入。解凍後のべちゃっと感も緩和されてよかった。
優秀賞
視力(ICL手術)
レーシックと似てるけど、眼内コンタクトレンズと呼ばれるものを挿入して視力を矯正する方式。
子供のころからずっとメガネとコンタクトレンズを行ったり来たりしてるうちに怠くなってきて一念発起。
施術自体は30分程度で痛みもなく終わるが術後1週間シャワーを浴びれなかったり目薬を頻繁に注す必要があったりと、前後の生活スタイルを考慮しないとならない。
その代わり効果は劇的で、メガネがないと外出るのも難しかったのがなんら困難なく生活できている。目が覚めた瞬間視界がクリアなのは感動。
まとめ
結構な散財をした1年だった気がするが来年はもっと散財したい。
Google Cloud 認定資格の試験を遠隔監視オンラインで受けてみた
Google Cloud Platform(以下GCP)には、GCPを用いた職務遂行能力を評価し認定する資格があります。
資格を取得するには、規定の試験を受け、合格する必要があり、試験は、オンサイト試験または遠隔監視オンライン試験いずれかを選択できます。
オンサイト試験は、テストセンターに行き、私物等をロッカーに入れた上で隔離環境のPCから受講しますが、
遠隔監視オンライン試験は自宅やオフィスなど任意の場所で受講可能な一方、 テストセンターと同程度の環境で受験していること を要件にし、カメラなどで常に監視されています。
この要件から、オンサイト試験でテストセンター*1で実施する方が面倒は少ないのですが、昨今の状況を鑑みて、人と物理的に接触することのない遠隔監視オンライン試験を受講しました。
受験した資格
Google Cloud Certified - Professional Data Engineer (Japanese)
私の受験環境
- 居住環境
- 大通りから一本奥まった低層マンション(1K)
- 一人暮らし
- 騒音が聞こえてくることは通常ない。
- PCはリビングに設置。 技術書などを詰めた大型本棚も同じ部屋にあり、カメラに映る位置。
- PC
受験前の準備と当日の流れ
前日まで
- 受験ガイドExam Procedures を参考にチェック
- 「Sentinel」という監視ツールをインストール
- 「生体認証プロファイル」を取得(カメラで顔を映す)
当日
- 試験開始15分前
- 常駐させている各種アプリを終了。(Docker, Krisp, Google driveなどなど…。)
- デスクからキーボードとポインティングデバイス以外をすべて撤去する。 撤去したものは視界に映らないようにした。
- 本人確認のためのパスポートを準備
- 試験開始10分前~試験開始まで
- 試験開始
トラブルや戸惑ったこと
- 試験開始前のカメラ撮影で試験官のリアクションが少なく、撮し方が合ってるのかどうなのかわからなかったので、こちらから「いかがでしょうか」「以上です」などのメッセージを送ったりしてました。*2
- 試験開始直後、問題文を小声でブツブツ読み上げていたところ、監視の要件に引っかかった?のか試験が中断した。 警告の文言を読んで理由がわかったのでOK押して再開した。
- 試験が終わりSentinelのウィンドウが閉じたのでブラウザに戻ると「トラブルが発生したので~~」のような文言が表示されwebassessorからログアウトされていた。 すわ試験無効か!?と焦ったが、再ログインして結果を確認したら合格となっており、got kotonaki。
まとめ
GCPの遠隔監視オンライン試験についての体験レポートは以上です。 今回のケースではさほどトラブルもなく順調に進みましたが、普段テレビ会議のセッティングになれていない場合は事前準備をすることをオススメします。 コロナ禍においては外出せずに試験を受けられる仕組みは大変有用なので、今後(なんならコロナ禍が収まってから)も積極的に利用したいです。
見知らぬGCPプロジェクトの利用状況を把握する方法あれこれ
前書き
管理者不在のGCPプロジェクトを渡され、何してるのかを調べて欲しいというタスクを振られたかわいそうな人向けにトリビアルなノウハウを共有します。
TL;DR
- Asset Inventoryでリソースの総量を把握する。
- 稼働状況をモニタリング、ログ、Billingなどから把握する。
- リソース同士の関連をIAMから探る。
- 引き継ぎはちゃんとやれ。たのむ。
前提
本文
本記事では、GCPが提供するコンソールをさっと眺めるだけである程度のざっくりとした構成を概観し、より詳細な調査をするための足がかりを得るノウハウを共有します。 各リソースの詳細までは踏み込みません。
利用するツール
この記事で触れるツールは以下です。 順番に説明しますが、実際はこれらのツールを相互に行き来しながら関連を探ることになります。
- Asset Inventory
- Cloud Monitoring
- Cloud Logging
- APIs & Services
- IAM
Cloud Asset Inventory
Cloud Asset Inventoryは、GCPプロジェクト内のリソースのメタデータを保有し、一覧化や検索が可能なサービスです。 利用は無料です。
Cloud Asset Inventoryを用いることで、どんなリソース(VM, GCS, BigQuery, VPN…)が作成されているのか、それらがどのlocationにあるのかを把握することができます。
Cloud Asset Inventoryは「IAM & Admin」配下から使用でき、以下のように、どのリソースがいくつ作成されているかを一覧できます。
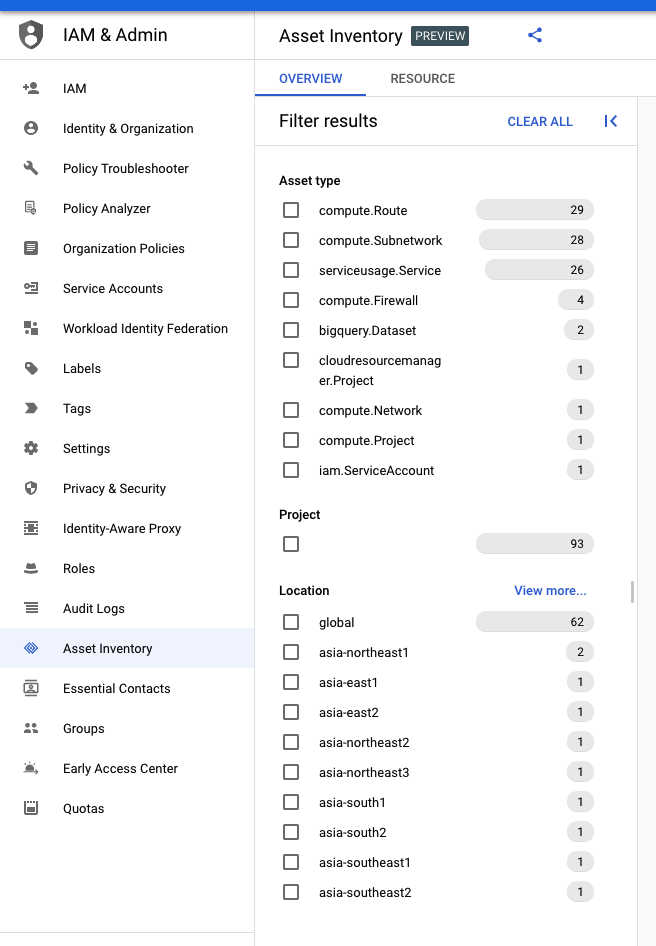
上の画像では、少なくともGAEのサービスが1つ、BigQueryのデータセットが2つ、VPNが1つとサブネットが多数あるといったことが伺い知れます。
コンソールからCSVダウンロードも可能です。
注意点としては、Cloud Asset Inventoryはあくまでリソースがあるかないかの静的な状況で、「実際に使われているかどうか」は判別できません。 「実際に使われているかどうか」は別のツールが必要になります。
Cloud Monitoring, Cloud Logging, APIs & Services
「実際に使われているかどうか」を把握するためのツールとしてはMonitoringとLogging*2とAPIs & Servicesがあります。 これらはGCPのリソースの利用状況と、なにかしらのイベントが起きていることを詳細に把握できるツールです。
Cloud Monitoring
ここでも「Resource dashboards」という形でリソースの有無が把握できます。
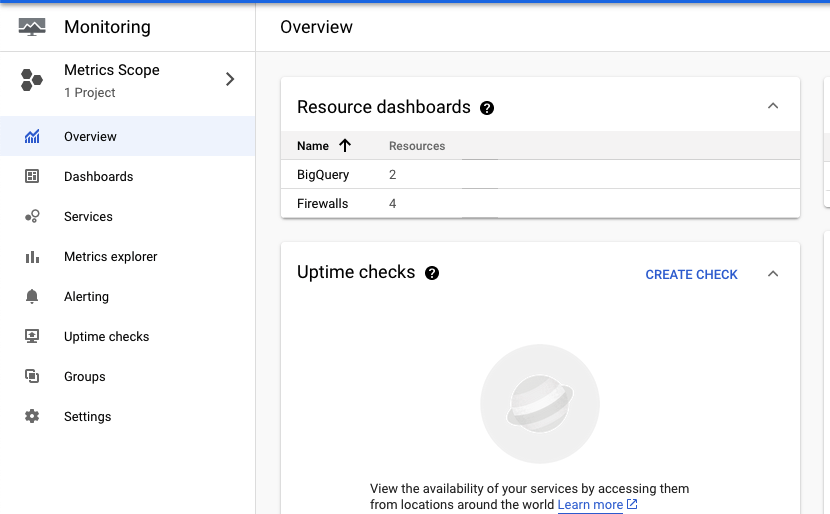
Cloud Monitoringは代表的なプロダクトについてはGCPが予め作成したダッシュボードがあり、稼働しているプロダクトが表示されます。 また、気の利いた前任者であれば、カスタムダッシュボードとしてそのプロジェクトで把握したいメトリクスをまとめたダッシュボードを発見できるかもしれません。*3
Cloud Logging
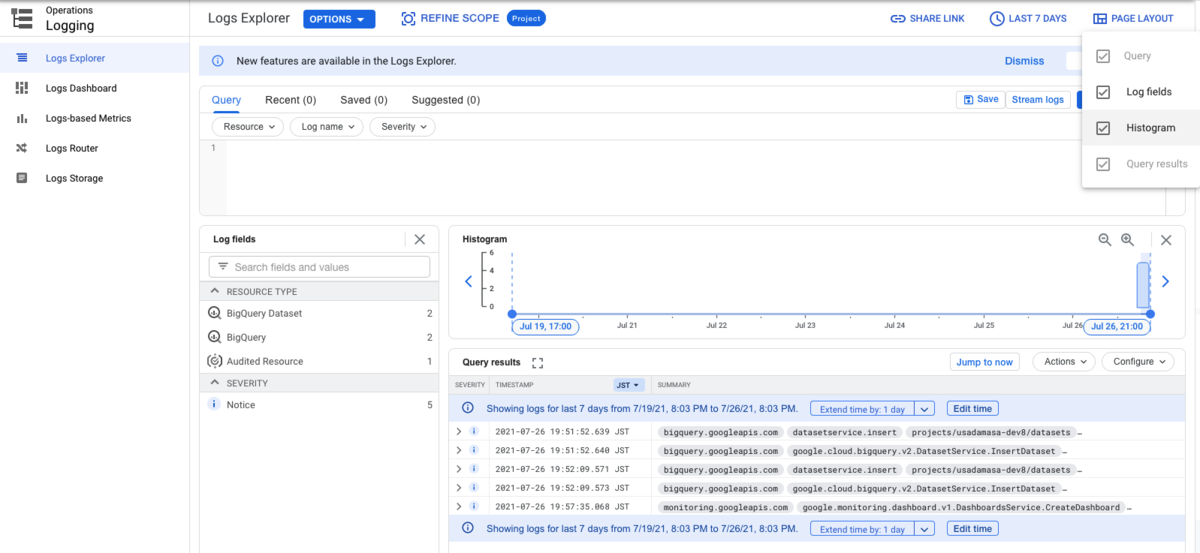
CloudLoggingは、各コンポーネントが出力したログエントリが集約されていて、なんのプロダクトが活発に動いているかが把握できます。 画面上の「PageLayout」から「Log Field」および「Histogram」をペインに表示しておくことで、どのリソースが直近どのような時系列と頻度で動いているかを知ることができます。
APIs & Services
GCPはリソースの各種操作をAPIを利用して行っており、「APIs & Services」はそのAPIの利用状況がわかるダッシュボードです。
このダッシュボードを参照することで、ヘビーに呼び出されているAPIはなにか、そのプロダクトはなにかを把握し、ワークロードの傾向をつかむことができます。
IAM
IAMを参照することで、どのアイデンティティ*4が何の権限を持っているかを把握することができます。
前任者がキチンと設計したかどうかで、IAMが細かく作成されているか、おおざっぱになっているか、あるいはデフォルトサービスアカウント*5一本槍かは異なります。
付与されている権限だけでなく、Recommenderという機能により、付与された権限のうち、実際には使われていない権限を把握することができます。 裏を返せば、実際に使われている権限も確認できます。
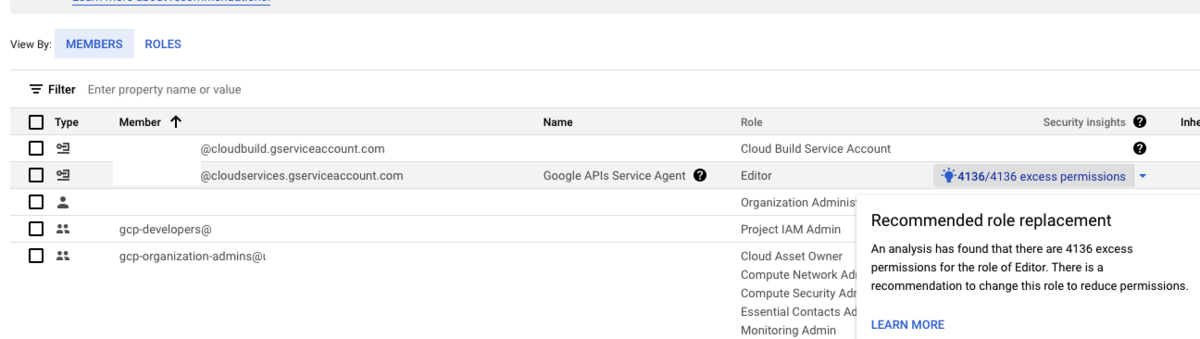
これらの情報から、以下が把握できます。
クロスプロジェクトの権限付与
GCPは、プロジェクトをまたいだ権限付与が容易に可能な方式です。 異なるプロジェクトに属するサービスアカウントから、調査しているプロジェクトに対する権限*8はコンソールから容易に把握できますが、一方でそのプロジェクトのアカウントが他のプロジェクトへの権限を持っている*9ことを知ることは事前の知識がなければ困難です。 後者の権限はBigQueryのDWH/マートなどを集約したプロジェクトを参照する方式で頻発するため、DWH/マートを保有するプロジェクト側での統制が重要となります。
サービスアカウントキーが発行されている場合
GCPは、サービスアカウントキーのjsonを発行することで、GCPサービス外からGCPの機能を利用することができます。
調査の過程で、このサービスアカウントキーが発行されていることが発覚した場合は、構成の把握の難易度が格段に上がることを覚悟してください。 サービスアカウントキーは一般に、GCP外のオンプレミスシステム、SaaSやAWSなどのパブリッククラウドで使われ、事前の知識がなければどこで利用されていることを把握することは困難です。
「少なくともまだ利用されているかどうか」は、使用状況のモニタリングから観測することができます。*10
まとめ
- GCPコンソールだけでも結構わかることはある。
- Cloud Asset Inventoryはここしばらく開発が活発なようなので要チェキ。
- いくら頑張っても知識が無い状態から要件定義、基本設計を導き出すことは基本的に不可能なので有識者を探すこと。*11
*1:roles/Viewer があればなんとかなります。
*2:ちょっと前までStackdriverと呼ばれていたもの
*3:期待しない方がいい
*4:ユーザアカウント、サービスアカウント、グループなど
*5:公式リファレンスではデフォルトサービスアカウントはプロダクションでは利用しないことを推奨しています。 https://cloud.google.com/iam/docs/service-accounts?hl=ja#default
*6:そのユーザとコンタクトを取り、ヒアリングすることで一気に道が開ける可能性はある。
*7:そのサービスアカウントがアタッチされているコンポーネントを簡単に知る方法はまだわかってない
*8:インバウンドって言えばいいのか?
*9:アウトバウンド?
*10:ロギングに接続元IPも出た気がする
*11:本当に運用に必要なドキュメントが何なのかを考える 近藤 誠司. 運用改善の教科書 ~クラウド時代にも困らない、変化に迅速に対応するためのシステム運用ノウハウ (Japanese Edition) (Kindle の位置No.837). Kindle 版.
ローカル開発用Dockerでユーザアカウント認証済みのgcloudを使う
サービスアカウントのキーを発行する必要はない。
version: "3.7" services: app: build: . volumes: - ~/.config/gcloud:/root/.config/gcloud:ro environment: - GCLOUD_PROJECT
argocdでSSOしたいときにclientSecretをSealedSecretで保持したい
忘れないうちに概要だけでもメモする。
Motivation
argocdでSSOするときにSSO先のcredential情報を平文でリポジトリにcommitしたくない。
解決方法
argocdのconfigmapからSecretを参照する機能を用い、 さらに参照先のSecretはSealedSecretで管理する。
段取り
- argocdをシュッと立ち上げる。
argocd-secretからserver.secretkeyを採取する(A)。- 使いたいSSOの
clientSecretからSecretを生成する(B)。 - (A)と(B)をマージしたSecretからSealedSecretを生成する。
- このとき、複合されるSecretの名前が
argocd-secretとなるように記述する。
- このとき、複合されるSecretの名前が
- argocdに元からある
argocd-secretにpatchを当て、sealedsecrets.bitnami.com/managed: "true"のannotationを付与する。 argocd-cmのclientSecretの値の先頭に$をつけて、Secretの値を参照できるようにする。- applyする。
ハマりポイント
sealedsecrets.bitnami.com/managed: "true" で勝つると思いきや生成タイミングの問題か server.secretkey が消えてしまい、 Unable to load data: server.secretkey is missing と怒られる。
Appendix
argocdのconfigmapからsecretsを参照する機能
https://github.com/argoproj/argo-cd/blob/6d44c4de413c2a5bbc6faf027a86d54a3e2ac8d0/docs/operator-manual/user-management/index.md#2-configure-argo-cd-for-sso
デフォルトで生成される server.secretkey について
https://github.com/argoproj/argo-cd/blob/v1.6.1/docs/operator-manual/argocd-secret.yaml#L21-L23
既存のSecretsを上書きしてSealedSecretでマネージする
github.com